

1. 캐스팅 유형
하나의 타입을 다른 타입으로 바꾸는 것.
데이터를 하나의 데이터 타입에서 다른 데이터 타입으로 전환하는 것
1. 값 타입 변환
의미를 유지하기 위해, 원본 객체와 다른 비트열 재구성
int a = 123456789; // 2의 보수
float b = (float)a; // 부동소수점(지수 + 유효 숫자)
cout << b;두 타입은 저장하는 방식이 완전히 다르다. int 타입은 2의 보수 형태를 취하고, float 타입은 부동소수점 형태를 취한다.
만약 위와 같이 캐스팅해서 출력하면 결과는 무엇이 나올까?

변환된 결과가 원본과 정확하게 일치하지 않는다. 왜 이런 결과가 나오는지 메모리를 직접 확인해 보자.
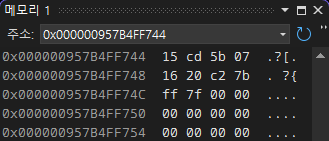
첫째 줄에 기입된 16진수 '075B CD15'는 10진수로 변환해 보면 123456789이다. 이를 2진수로 표현하면 '0000 0111 0101 1011 1100 1101 0001 0101'과 같다.
- 리틀 엔디안 방식으로 메모리에 값이 저장되기 때문에 오른쪽에서 왼쪽으로 수를 읽어야 한다.
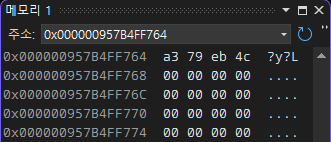
특이하게도 값이 전혀 다르게 저장돼 있다. 위에서 언급했듯 float 타입과 int 타입은 비트를 구성하는 방식이 다르기 때문에, 정수 123456789와 가장 근접한 값을 갖도록 비트열이 재구성된 것이다.
2. 참조 타입 변환
비트열을 재구성하지 않고, 데이터를 바라보는 관점만 변경
아래 코드를 실행해서, 메모리를 다시 한번 확인해 보자.
int a = 123456789; // 2의 보수
float b = (float&)a; // 부동소수점(지수 + 유효 숫자)
cout << b;
a는 아까와 동일한 값이 들어있는 것을 확인할 수 있다.

이번에는 비트열이 변하지 않고 a와 동일한 값이 들어있는 것을 확인할 수 있다.
float는 int와 다른 비트 구성을 갖기 때문에, 데이터 자체는 똑같이 유지되지만 바라보는 관점이 달라져 의미가 완전히 달라진다.
이런 primitive 타입 변환에는 거의 사용되지 않지만, 후술 할 '포인터 타입 캐스팅'에서 이 규칙이 적용된다.
2. 안전한/안전하지 않은 변환
1. 안전한 변환
의미가 항상 완전히 일치하는 경우
어떤 물건이 담겨 있는 바구니를 생각해 보면, 같은 종류의 바구니에서 더 큰 바구니로 옮기는 경우 안에 든 물건을 온전하게 전부 옮길 수 있다.
변수 또한 일종의 바구니라 할 수 있다. 즉, 같은 타입이면서 크기가 더 큰 변수로 데이터를 옮기는 것은 문제가 없다. 예를 들어 char 타입에서 short 타입으로, short 타입에서 int 타입으로, int 타입에서 long long 타입으로의 이동이 있겠다. 이를 업캐스팅이라 한다.
int a = 123456789;
long long b = a;
cout << b;

사실 2진수로 생각해 보면 더 명확한데, 아래 2줄로 표현되는 32비트 크기의 int 타입 변수가 데이터를 온전하게 표현한다면 4줄을 모두 사용하는 64비트 크기의 long long 타입 변수는 당연하게도 데이터를 온전하게 표현할 수 있다.
2. 불안전한 변환
의미가 항상 일치한다고 보장할 수 없는 변환
불안전한 변환은 위에서 살펴본 int -> float 캐스팅과 같이 다른 타입으로 변환하거나, 크기가 큰 타입에서 작은 타입으로 변환하는 경우를 의미한다. 후자의 경우를 다운캐스팅이라 부른다.
int a = 123456789;
float b = a;
short c = a;
cout << b << "\n" << c;
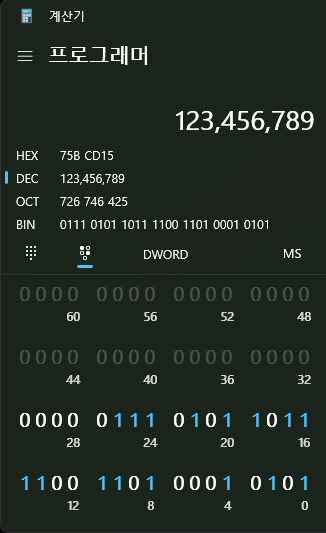
b의 경우 위에서 살펴봤듯 의미를 유지하기 위해 최대한 비슷한 값이 들어가 있으나 여전히 정확히 일치하는 것은 아니며, c의 경우 공간이 작아짐에 따라 데이터가 변형된 것을 알 수 있다.
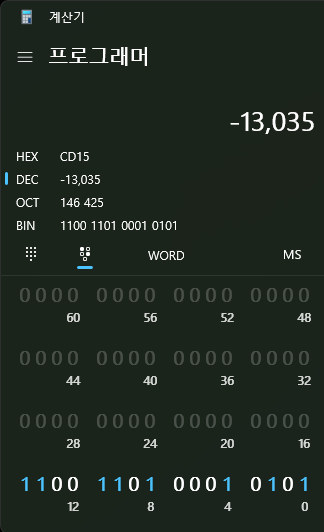
short 타입은 16비트 공간을 갖기 때문에, 32비트에 걸쳐 표현된 123456789란 수를 온전히 표현하지 못한다. 위 계산기 이미지처럼 두 번째 줄이 제거되고, 남은 첫 번째 줄의 수를 표현한 -13035라는 값이 나오는 것을 알 수 있다.
그렇기 때문에 형변환 시 항상 데이터 손실이 일어나지 않는지 주의를 기울여야 한다.
3. 암시적/명시적 변환
1. 암시적 변환
이미 알려진 형 변환 규칙에 따라 컴파일러가 자동으로 형 변환
int a = 123456789;
float b = a; // 암시적
float c = (float)a; // 명시적
cout << b << "\n" << c;
변수 b에는 int 타입 변수 a를 별도의 형 변환 없이 바로 대입한다. 그러나 변수 c와 같이 명시적으로 (float)를 표기해 준 것과 동일한 결과를 출력한다.
이것은 내부적으로 컴파일러가 알려진 추론 규칙에 입각해 자동으로 값 타입 변환을 수행해 줬기 때문이다.

다만 코드를 빌드하면 컴파일러가 위와 같은 경고 메시지를 출력한다. 다른 타입으로의 변환은 불안전한 형변환이기 때문에 컴파일러가 '데이터가 손실될 수 있습니다.'란 경고를 출력하는 것이다. 일부 프로젝트의 경우 데이터 손실을 엄격하게 막기 위해 컴파일러 경고 수준을 높여서 빌드가 안되도록 하기도 한다.
2. 명시적 변환
알려진 타입 추론에 입각해 암시적으로 변환을 해준다는 말은 곧, 모든 타입 간 변환을 자동으로 처리해 주는 것은 아니란 뜻이 된다.
int a = 123456789;
int* b = a;
예를 들어 위와 같이 int 타입 변수를 포인터 타입 변수로 변환하는 것은 일반적인 관점에서 적절하지 않아 에러를 발생시킨다.
int a = 123456789;
int* b = (int*)a;
cout << b;
만약 프로그래머가 의도적으로 변환하고자 하면, 위와 같이 변환하고자 하는 타입을 명시하면 에러가 발생하지 않고 정상적으로 빌드가 가능하다.
4. 클래스 간 변환
1. 연관 없는 클래스 간 변환
1. 값 타입 변환
class Knight
{
public:
int _hp = 10;
};
class Dog
{
public:
int _age = 1;
int _cuteness = 2;
};
int main()
{
Knight k;
Dog d1 = k;
Dog d2 = (Knight)k;
return 0;
}

현재 Knight와 Dog라는 클래스 간에는 아무런 연관이 없다. 이 경우 Knight 클래스 타입 변수 k를 Dog 클래스 변수로 변환하고자 하면 암시적이든 명시적이든 에러가 발생한다. 이와 같은 값 타입 변환은 일반적으로 불가능하다. 아래에서 얘기하는 참조 타입 변환과 달리 '실제 데이터'를 대상으로 변환이 일어나기 때문이다.
만약 값 타입 변환을 수행하고 싶다면 아래와 같이 타입 변환 생성자 또는 타입 변환 연산자를 추가해줘야 한다.
class Dog
{
public:
Dog(const Knight& k) // 타입 변환 생성자
{
_age = k._hp;
}
operator Knight() // 타입 변환 연산자
{
return (Knight)(*this);
}
public:
int _age = 1;
int _cuteness = 2;
};
int main()
{
Knight k;
Dog d = (Knight)k; // 타입 변환 생성자로 인해 가능
Knight k2 = d; // 타입 변환 연산자로 인해 가능
return 0;
}이 경우 Dog 타입 변수에 Knight 타입 변수를 암시적으로든 명시적으로든 대입해도 에러가 발생하지 않으며, 역으로 Dog 타입 변수를 Knight 타입 변수에 넣어도 문제가 발생하지 않는다.
2. 참조 타입 변환
Knight k;
Dog& d = k; // Dog의 참조 타입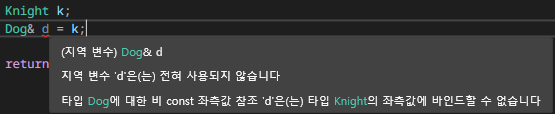
C++에서 참조 타입은 '별칭'으로서 기능을 하기도 한다. 여기서는 Knight 타입 변수 k를 Dog 타입의 'd'라는 이름으로도 부르겠다는 의미가 되는데, Knight는 Dog와 전혀 연관이 없기 때문에 타입 변환 생성자/연산자를 정의해도 컴파일러가 이를 허용하지 않는다. 즉 타입 변환 생성자/연산자는 값 타입 변환에서만 적용되는 것을 알 수 있다.
이를 가능하게 하려면 아래와 같이 명시적으로 타입 변환을 수행해야 한다.
Knight k;
Dog& d = (Dog&)k;이 코드가 문법적으로 에러가 없는 이유는, 참조 타입은 어셈블리 단계에서 포인터와 완벽하게 동일하기 때문이다.
- 포인터는 주소를 담는 공간이며, 그 공간에 담긴 주소를 타고 가면 해당 타입의 데이터가 있음을 의미한다.
- 즉 '변수 d에 담긴 주소를 타고 가면 Dog 타입 데이터가 있다'라고 주장하는 것이기 때문에, 실제로 Dog 타입 데이터가 아닐지라도 문법적으로는 틀린 말이 아니게 되는 것이다.
즉 주소 자체는 데이터를 건드리는 것이 아닌, 아래 그림과 같은 형태만 구축한 것이다.

C언어에서 메모리 공간을 동적으로 할당받으려면 malloc() 함수를 사용하는데, 이 함수의 반환값은 void* 타입이다. 즉 동적으로 공간을 할당하는 시점에는 실질적으로 어떤 데이터를 갖는지 알 수가 없다. 단지 할당받은 공간을 프로그래머가 의도하는 타입으로 취급하여 사용하는 것이다. 이러한 점 때문에 포인터 변수는 해당 주소가 가리키는 데이터가 '진짜로 그 타입의 데이터인지'를 검사하지는 않는다.
이렇게 하면 문법적으로 에러가 발생하지는 않지만 매우 위험한 코드가 된다. Knight와 Dog는 전혀 다른 메모리 구조를 가지고 있기 때문에, 현재 변수 d는 엉뚱한 메모리 영역을 침범하고 있는 것과 다를 바 없다.
- Knight 클래스는 _hp 변수만 가지고 있고, Dog 클래스는 _age 변수와 _cuteness라는 2가지 변수를 들고 있다.
- 이런 상황에서 변수 d를 통해 _cuteness 변수를 접근하면, 실제로는 Knight 클래스의 메모리 구조를 갖기 때문에 엉뚱한 메모리 공간에 접근하게 되는 것이다.
2. 상속 관계에 있는 클래스 간 변환
1. 값 타입 변환
사실 대부분의 값 타입 변환은 논리적인 흐름에 맞게 이뤄진다. 이 경우에도 마찬가지인데, 아래와 같은 코드를 확인해 보자.
class Dog
{
public:
int _age = 1;
int _cuteness = 2;
};
class BullDog : public Dog
{
public:
bool _french;
};
int main()
{
Dog dog;
BullDog bullDog = dog;
return 0;
}
모든 Dog은 BullDog이 아니기 때문에 어찌 보면 당연히 안 되는 변환이기도 하다. 또한 BullDog에만 있는 _french 변수로 인해, Dog 타입 변수 만으로는 BullDog 타입 변수를 세팅하는 것이 불가능하다.
만약 반대로 BullDog 타입 변수를 Dog 타입 변수에 대입하면 어떻게 될까?
BullDog bullDog;
Dog dog = bullDog;
정상적으로 빌드가 되는 것을 알 수 있다. BullDog은 Dog로부터 상속받은 클래스이기 때문에, 기본적으로 Dog의 정보를 다 들고 있어 Dog 변수의 데이터를 모두 세팅할 수 있다.
요약하면 자식 클래스 -> 부모 클래스는 가능, 부모 클래스 -> 자식 클래스는 불가능이다.
2. 참조 타입 변환
Dog dog;
BullDog& bullDog = dog;
앞서 살펴본 참조 타입 변환과 비슷하게, 메모리 영역 침범을 막기 위해 더 큰 메모리 구조를 갖는 BullDog으로의 암시적 변환은 허용하지 않는다. 에러를 없애고 싶다면 아래와 같이 명시적으로 변환해야 한다.
Dog dog;
BullDog& bullDog = (BullDog&)dog;
반대로 BullDog 참조 변수에 Dog 변수를 대입하는 경우는 어떨까?
BullDog bullDog;
Dog& dog = bullDog;

이 경우엔 암시적 변환도 허용한다. BullDog이 Dog의 요소를 모두 포함하는 더 큰 메모리 구조를 갖기 때문에, 안전한 형변환으로 동작해 암시적 변환이 가능하다.
요약하면 자식 클래스 -> 부모 클래스는 가능, 부모 클래스 -> 자식 클래스는 명시적으로만 가능이다.
5. 포인터 타입 변환
Item 클래스를 아래와 같이 정의해 보자.
- _dummy 데이터는 클래스가 비대해지는 것을 의도하기 위해 정의하였다.
- 실제로 게임에서 Item 같은 클래스는 강화 정보, 오너 정보 등 많은 정보를 들고 있다.
class Item
{
public:
Item()
{
cout << "Item()\n";
}
Item(const Item& item)
{
cout << "Item(const Item& item)\n";
}
~Item()
{
cout << "~Item()\n";
}
public:
int _type = 0;
int _id = 0;
char _dummy[4096]{};
};1. 들어가기에 앞서
int main()
{
Item item; // 1
Item* item = new Item(); // 2
}
일반적으로 Item에 대한 인스턴스를 생성한 것과, new 연산자를 이용해 Item에 대한 인스턴스를 생성한 것은 서로 다르게 데이터를 보관한다. 일반적으로 생성한 것은 Stack 메모리에 모든 데이터에 대한 공간이 할당되었고, new를 통해 생성된 포인터 인스턴스는 Stack 메모리에 주소값이 보관돼 있고, 해당 주소를 타고 들어간 곳에 실제 데이터가 존재한다. 그 영역은 Heap 메모리이다.
잠시 아래 코드에서 각 인스턴스들의 생성자와 소멸자가 어떻게 동작하는지 살펴보자.
int main()
{
{
Item item; // breakpoint
Item* item2 = new Item();
}
return 0;
}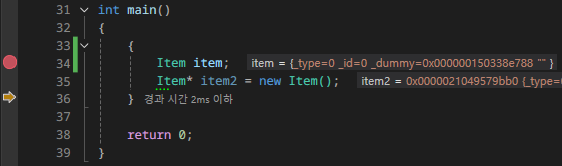

현재 일반적으로 생성한 인스턴스와 동적 할당으로 생성한 인스턴스 모두 생성자가 동작하는 것을 확인할 수 있다.
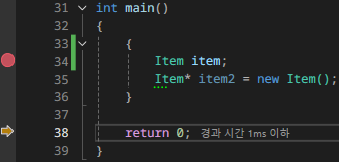

그런데 내부 스코프를 벗어나니 소멸자가 한 번만 호출된 것을 확인할 수 있다.
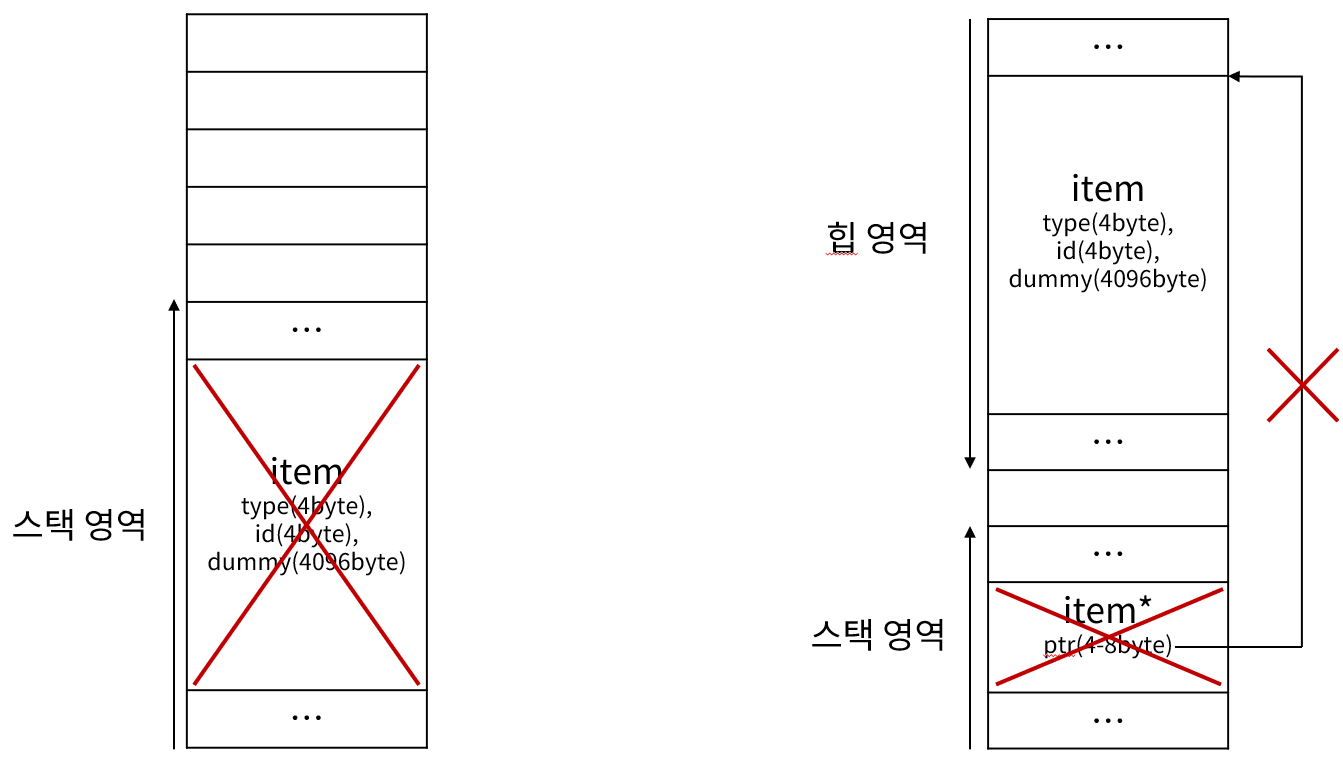
스택 메모리에 저장된 데이터들은 유효 스코프를 벗어나면 자동적으로 메모리에서 해제된다. 그렇기 때문에 일반적으로 생성한 인스턴스는 데이터가 해제되며 소멸자가 호출된다.
반면 동적 할당으로 생성된 인스턴스는 스택 메모리에 힙 메모리에 존재하는 인스턴스를 가리키는 주소값만 들고 있기 때문에, 주소값만 지워지고 실제 데이터는 지워지지 않는다. 그래서 소멸자가 호출되지 않는다.
이 경우 힙 메모리에 존재하는 데이터에 접근할 수 있는 방법이 사라지는 문제가 발생한다. 프로그램이 종료되기 전까지 힙 메모리에 계속 존재하지만, 어디서도 접근할 수 없는 이런 현상을 메모리 누수(Memory Leak)라고 한다. 보통 메모리 누수는 즉각 프로그램에 영향을 주지 않고, 서서히 메모리 사용량이 증가하다가 어느 시점에 가용 메모리 용량이 부족해져 크래시가 발생한다. 이런 현상을 막기 위해 아래와 같이 반드시 메모리 해제, delete를 해줘야 한다.
int main()
{
{
Item item;
Item* item2 = new Item();
delete item2; // 해제
}
return 0;
}
이번에는 아래와 같이 함수를 호출해 보자.
void ItemFtn(Item item)
{
}
void ItemPtrFtn(Item* item)
{
}
int main()
{
{
Item item;
Item* item2 = new Item();
ItemFtn(item); // breakpoint
ItemFtn(*item2); // 값을 꺼내서 전달
ItemPtrFtn(&item); // 포인터를 받으므로 주소 전달
ItemPtrFtn(item2);
delete item2;
}
return 0;
}

ItemFtn 함수를 호출하니 복사 생성자와 소멸자가 호출되는 것을 알 수 있다. 인자로 넘겨받는 Item 타입 또한 객체이며, 참조 형식이 아닌 복사 형식으로 넘겨받기 때문에 위와 같은 결과가 출력되는 것이다. 포인터 변수의 값을 꺼내서 넘겨주는 것 역시, 결국 데이터를 복사하는 것이기 때문에 복사 생성자 & 소멸자가 호출되는 것을 알 수 있다.

현재 item 변수는 stack 메모리에 상주하므로 4104바이트 크기를, item2 변수는 주소만 들고 있기 때문에 8바이트 크기만 갖는 것을 알 수 있다. 복사 생성자가 호출된다는 것은 4104바이트라는 큰 크기의 데이터가 통째로 복사되는 것을 의미하므로, 함수 인자로 데이터를 넘길 때 복사 형식으로 넘기는 것은 항상 주의해야 한다.


반면 포인터를 인자로 받는 ItemPtrFtn을 호출할 때는, 실제 데이터를 복사해서 넘기는 것이 아닌 주소값만 넘기는 것이므로 생성자나 소멸자가 호출되지 않는 것을 알 수 있다.
2. 연관성 없는 클래스 간 포인터 변환
앞서 포인터 변환은 참조 타입 변환의 규칙이 적용된다고 언급하였다. 이를 한 번 확인해 보기 위해 아래와 같이 코드를 작성해 보자.
class Knight
{
public:
int _hp = 0;
};
class Item
{
public:
Item()
{
cout << "Item()\n";
}
Item(const Item& item)
{
cout << "Item(const Item& item)\n";
}
~Item()
{
cout << "~Item()\n";
}
public:
int _type = 0;
int _id = 0;
char _dummy[4096]{};
};
int main()
{
{
Knight* knight = new Knight();
Item* item = knight;
}
return 0;
}
Item 타입 포인터 변수에 Knight 인스턴스를 그냥 대입하려고 하니 컴파일러가 에러를 발생시킨다.
int main()
{
{
Knight* knight = new Knight();
Item* item = (Item*)knight;
}
return 0;
}
그런데 이처럼 명시적으로 캐스팅을 수행하면 정상적으로 빌드가 되는 것을 확인할 수 있다. 현재 아래 그림과 같은 구조가 잡힌 것이다.
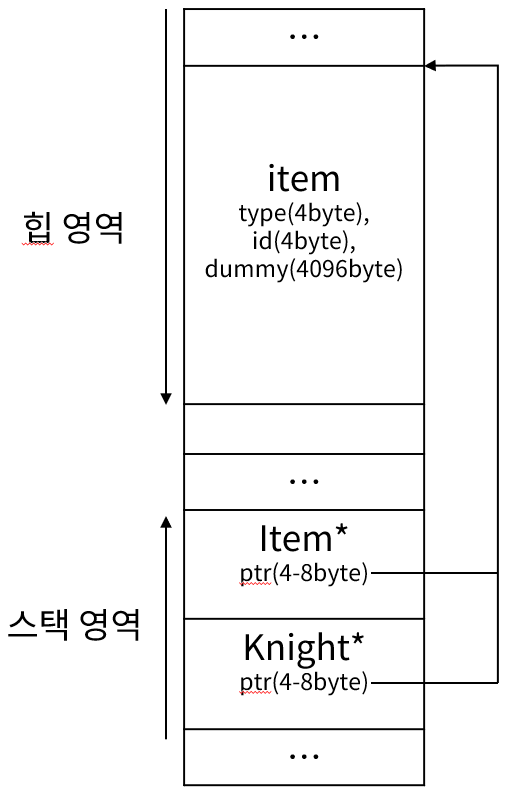
이러한 상황에서, item 변수에 접근해 데이터를 건드리면 어떻게 될까?
int main()
{
{
Knight* knight = new Knight();
Item* item = (Item*)knight;
item->_type = 1;
item->_id = 2;
}
return 0;
}
Item 타입은 type, id, dummy로 큰 데이터를 갖도록 설계했는데, 현재 Knight 타입 인스턴스를 강제로 대입했기 때문에 똑바로 초기화된 건 맨 윗줄 00000000으로 세팅된 type 데이터 하나밖에 없다.
- Knight의 _hp 변수와 Item의 _type 변수가 둘 다 int 타입이며 메모리 상에서 첫 번째 오프셋의 위치에 존재하기 때문에 우연히 일치한 것이다.
두 번째 줄부터는 id 변수와 dummy 변수에 대한 영역인데, Knight 인스턴스 상에서는 초기화할 수 없는 영역이라 현재 이상한 값이 세팅된 것을 확인할 수 있다.
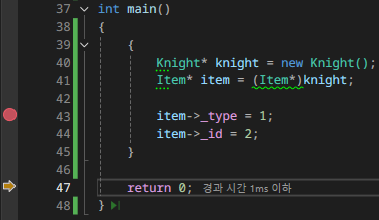
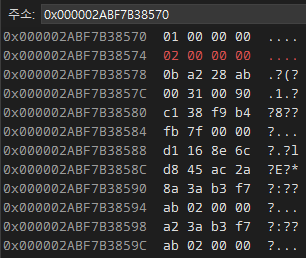
이 상황에서 type 변수와 id 변수를 세팅해 보자. type 변수는 Knight의 hp 변수에 대응되는 공간이 있어 건드려도 문제가 되지 않으나, id 변수는 유효하지 않은 메모리 공간을 침범해 값을 쓰는 동작이 수행한다. 이런 경우 크래시가 발동해야 다행이며, 보통은 메모리가 오염된 상태로 동작하다가 한참 뒤(심하면 일주일 뒤)에 다른 곳에서 문제가 발생하곤 한다. 이러면 원인 추적이 매우 힘들어지는 상황이 된다.
int main()
{
{
Knight* knight = new Knight();
Item* item = (Item*)knight;
item->_type = 1;
item->_id = 2;
delete knight;
}
return 0;
}
위에서 'fdfdfdfd'란 값이 세팅된 것을 확인했는데, 이는 디버그 모드에서 컴파일러가 자동으로 채우는 특수한 값이다. 현재 delete 코드가 동작하면서 메모리에 접근했는데, 이 특수한 값을 만나게 되면서 컴파일러가 자동으로 에러(HEAP CORRUPTION DETECTED)라 판정하고 프로그램을 강제 종료시킨다.
3. 상속 관계에 있는 클래스 간 변환
상속 관계를 위해 아래와 같이 Item을 상속받은 클래스를 추가해 보자.
class Item
{
public:
Item()
{
cout << "Item()\n";
}
Item(int type)
: _type(type)
{
cout << "Item(int)\n";
}
Item(const Item& item)
{
cout << "Item(const Item& item)\n";
}
~Item()
{
cout << "~Item()\n";
}
public:
int _type = 0;
int _id = 0;
char _dummy[4096];
};
enum EItemType
{
WEAPON = 1,
ARMOR = 2,
};
class Weapon : public Item
{
public:
Weapon()
: Item(EItemType::WEAPON)
{
cout << "Weapon()\n";
_damage = rand() % 100; // 테스트를 위해 랜덤 값으로 데미지 세팅
}
~Weapon()
{
cout << "~Weapon()\n";
}
public:
int _damage = 0;
};
class Armor : public Item
{
public:
Armor()
: Item(EItemType::ARMOR)
{
cout << "Armor()\n";
}
~Armor()
{
cout << "~Armor()\n";
}
public:
int _defense = 0;
};1. 부모 클래스 -> 자식 클래스
int main()
{
{
Item* item = new Item();
Weapon* weapon = item;
delete item;
}
return 0;
}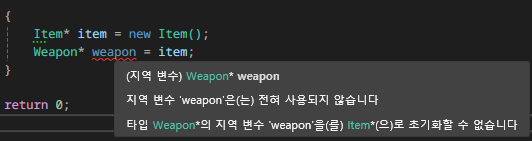
명시적 캐스팅 없이 자식 클래스 타입 인스턴스에 부모 클래스 타입 인스턴스를 대입하려고 하면 에러가 발생한다. 모든 Item이 Weapon임은 보장할 수 없기 때문이다. 그냥 Item일 수도, Armor일 수도 있다. 즉 메모리 크기가 작은 타입 변수에서 큰 타입 변수로 변환한다는 것은, 작은 크기의 타입에서 정의한 영역을 벗어난 공간도 접근한다는 의미가 되므로 불안전한 캐스팅이다.
int main()
{
{
Item* item = new Item();
Weapon* weapon = (Weapon*)item;
weapon->_damage = 10;
delete item;
}
return 0;
}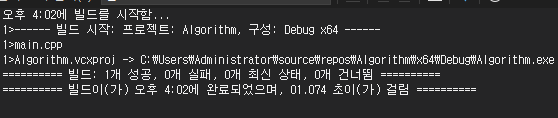

명시적으로 캐스팅하면 빌드는 통과하나, damage는 Item 클래스에선 정의되지 않은 데이터이므로 메모리 영역을 침범, 위에서 얘기한 대로 컴파일러가 에러를 발생시켜 프로그램을 강제 종료시킨다.
2. 자식 클래스 -> 부모 클래스
이번에는 반대로 자식 클래스 타입 인스턴스를 부모 클래스 타입 변수에 할당해 보자.
int main()
{
{
Weapon* weapon = new Weapon();
Item* item = weapon;
delete weapon;
}
return 0;
}이번에는 명시적으로 캐스팅하지 않아도 아무런 에러가 발생하지 않는다. Weapon은 Item을 상속받은 클래스이기 때문에 기본적으로 Item의 데이터를 모두 포함하고 있다. 즉 모든 Weapon은 Item으로도 간주할 수 있다. 그렇기 때문에 컴파일러가 안전하다고 판단한 것이다.
3. 이 기능이 왜 필요한가?
한번 Item들을 보관하는 인벤토리를 설계한다고 가정해 보자.
int main()
{
srand((unsigned int)time(nullptr));
Item* inventory[20]{};
for (int i = 0; i < 20; ++i)
{
int random = rand() % 2;
if (random & 1)
{
inventory[i] = new Weapon();
}
else
{
inventory[i] = new Armor();
}
}
return 0;
}인벤토리가 Armor, Weapon를 모두 보관할 수 있도록 하려면, 아래와 같이 부모인 Item 타입 인스턴스를 들고 있도록 선언하면 된다. 위에서 살펴본 것처럼, 자식 클래스 타입 인스턴스는 부모 클래스 타입의 데이터를 모두 들고 있기 때문에 안전하게 할당할 수 있다. 이 덕에 하위 클래스들을 공통된 부모 클래스 타입 하나로 관리할 수 있는 장점이 생긴다.
인벤토리에 저장된 아이템을 다시 확인, 사용하고자 할 때는 아래와 같이 코드를 작성할 수 있다.
for (int i = 0; i < 20; ++i)
{
Item* item = inventory[i];
if (item == nullptr)
{
continue;
}
if (item->_type == EItemType::WEAPON)
{
Weapon* weapon = (Weapon*)item;
cout << "Weapon Damage: " << weapon->_damage << "\n";
}
else if (item->_type == EItemType::ARMOR)
{
Armor* armor = (Armor*)item;
}
}
위에서 언급했듯 자식 클래스 타입 변수에 부모 클래스 타입 인스턴스를 별도의 확인 없이 할당하는 것은 매우 위험한 작업이기 때문에, type 값을 이용해 검사를 하고 캐스팅을 수행한다.
- 아까 Item 클래스 코드를 작성할 때 type 정보를 기입했기 때문에, type 값을 가지고 Weapon과 Armor을 구분할 수 있다.
- 예를 들어, type이 WEAPON이라는 것은 원본 데이터를 생성할 때부터 Weapon의 인스턴스였다는 것을 의미한다.
물론 최초에 type을 세팅할 때 실수로 잘못된 값을 세팅할 수도 있다. 예를 들어 Armor의 타입을 Weapon으로 세팅한 경우 아래와 같은 결과가 출력된다.
class Armor : public Item
{
public:
Armor()
: Item(EItemType::WEAPON)
{
cout << "Armor()\n";
}
~Armor()
{
cout << "~Armor()\n";
}
public:
int _defense = 0;
};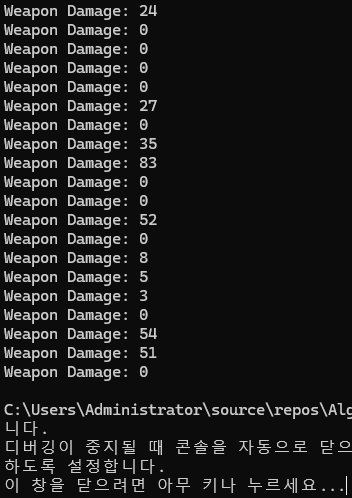
여기서 Damage가 0으로 출력되는 것은 실제 데이터가 Armor라 거기에 세팅된 _defense 값이 출력된 것이다. 지금은 다행히 구조는 같아 잘못된 값을 출력할 뿐이지만, 만약 Weapon과 Armor가 완전히 다른 메모리 구조를 가진다면 훨씬 더 큰 문제가 발생할 수도 있다.
4. 가상 소멸자
이제 인벤토리에 저장된 Item 데이터들을 소멸시키고자 한다. 이를 위해 다음과 같이 코드를 작성하고 실행해 보자.
int main()
{
srand((unsigned int)time(nullptr));
Item* inventory[20]{};
for (int i = 0; i < 20; ++i)
{
int random = rand() % 2;
if (random & 1)
{
inventory[i] = new Weapon();
}
else
{
inventory[i] = new Armor();
}
}
for (int i = 0; i < 20; ++i)
{
Item* item = inventory[i];
if (item == nullptr)
{
continue;
}
delete item;
}
return 0;
}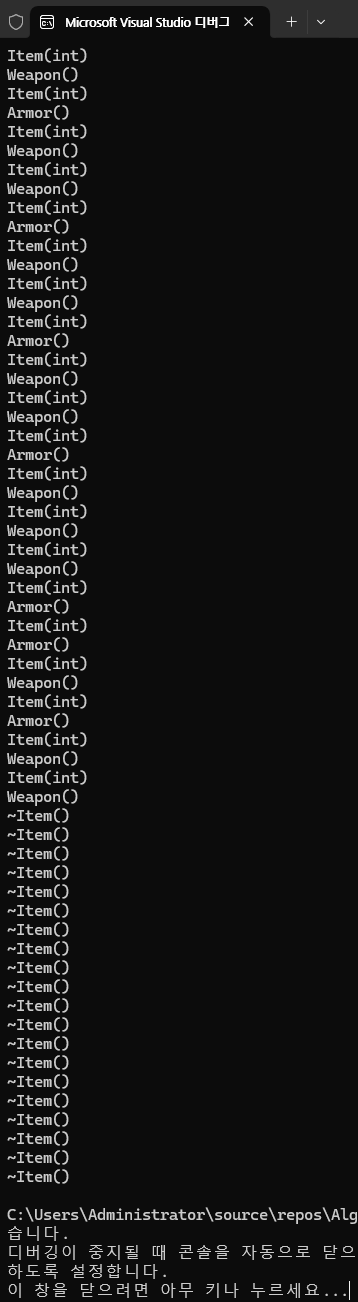
놀랍게도, Weapon과 Armor 상관없이 Item 소멸자만 실행되는 것을 확인할 수 있다. Weapon과 Armor는 Item 클래스를 상속받았기 때문에 메모리 상으로 Item 데이터 + a를 들고 있는 형태가 된다. 그렇기 때문에 자식 클래스가 추가로 들고 있는 데이터 또한 소멸하려면 자식 클래스의 소멸자 또한 호출되어야 한다. 자식 소멸자가 호출되도록 아래와 같이 코드를 수정해 보자.
for (int i = 0; i < 20; ++i)
{
Item* item = inventory[i];
if (item == nullptr)
{
continue;
}
if (item->_type == EItemType::WEAPON)
{
Weapon* weapon = (Weapon*)item;
delete weapon;
}
else if (item->_type == EItemType::ARMOR)
{
Armor* armor = (Armor*)item;
delete armor;
}
}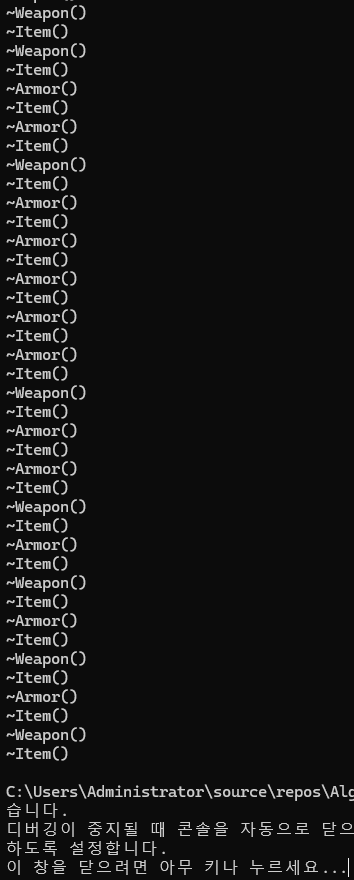
이제는 Weapon과 Armor의 소멸자가 호출된 뒤, Item의 호출자가 호출되는 것을 확인할 수 있다.
그런데 왜 이렇게 명시적으로 캐스팅을 해야만 자식 클래스의 소멸자가 호출될까? 이전에 살펴본 함수 호출 규칙을 다시 한번 떠올려보자: https://9ky0.tistory.com/5
[C++] 다형성(Polymorphism)과 가상 함수(Virtual Function)
1. 다형성이란?Polymorphism이란 단어를 보면 'Poly'라는 접두어와 'Morph'라는 단어가 합쳐져 '형태의 다양성'이라는 뜻을 가진다는 것을 알 수 있다.Poly는 같은 종류의 무언가가 많다는 뜻으로, 폴리곤
9ky0.tistory.com
class Item
{
public:
...
void Test()
{
cout << "Item::Test()\n";
}
public:
int _type = 0;
int _id = 0;
char _dummy[4096];
};
enum EItemType
{
WEAPON = 1,
ARMOR = 2,
};
class Weapon : public Item
{
public:
...
void Test()
{
cout << "Weapon::Test()\n";
}
public:
int _damage = 0;
};
class Armor : public Item
{
public:
...
void Test()
{
cout << "Armor::Test()\n";
}
public:
int _defense = 0;
};
void Test(Item* item)
{
item->Test();
}
int main()
{
Weapon* weapon = new Weapon();
Item* item = weapon;
Test(item);
delete weapon;
return 0;
}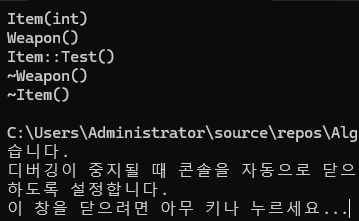
위와 같이 Test 함수를 각각 추가해 재정의가 발생하도록 한 상황에서, Weapon 타입 변수에 Item 인스턴스를 대입해 Test 함수를 호출하더라도 정적 바인딩으로 동작해 Item의 Test가 호출되는 것을 지난 게시글에서 확인했었다.
class Item
{
public:
...
virtual void Test()
{
cout << "Item::Test()\n";
}
public:
int _type = 0;
int _id = 0;
char _dummy[4096];
};
실제 타입에 맞는 메서드를 호출하도록 하려면, 위와 같이 virtual 키워드를 추가해 동적 바인딩이 되도록 코드를 수정했어야 했다. 이는 virtual 키워드로 가상 함수 추가 시 가상 함수 테이블이 생성, 이 테이블을 이용해 부모/자식 클래스에 존재하는 메서드를 적절히 찾아 수행할 수 있도록 동작한다고 얘기했었다.
소멸자 또한 일종의 함수이므로, 같은 원리로 자식 클래스에 존재하는 소멸자를 자동으로 호출되게 하려면 소멸자에 virtual 키워드를 붙여줘야 한다. 이렇게 소멸자 자체도 가상 함수로 취급되도록 하는 것을 가상 소멸자라 부른다.
class Item
{
public:
...
virtual ~Item()
{
cout << "~Item()\n";
}
public:
int _type = 0;
int _id = 0;
char _dummy[4096];
};
int main()
{
...
for (int i = 0; i < 20; ++i)
{
Item* item = inventory[i];
if (item == nullptr)
{
continue;
}
delete item; // Item 타입 변수를 즉시 delete 한다.
}
return 0;
}
C++에서 소멸자에 virtual 키워드를 붙이는 것은 매우 중요한 내용이니 절대로 까먹어서는 안 된다.
6. 캐스팅 연산자
이제껏 글에서 명시적으로 캐스팅하기 위해 작성했던 문법은 C-Style 캐스팅 연산자이다.
Weapon* weapon = new Weapon();
Item* item = (Item*)weapon; // C-Style CastingC-Style 캐스팅은 동일한 형태(문법)로 정말 다양한 종류의 캐스팅을 수행할 수 있는데,
- int <-> float와 같은 기본 타입 간 변환도 할 수 있고
- Player <-> Knight와 같이 상속 관계에서의 포인터 변환도 할 수 있었으며
- 상수성(const)을 제거하는 데 사용할 수도 있고
- 전혀 다른 타입 간 포인터 변환도 수행할 수 있다
그렇다 보니 각각의 캐스팅이 어떤 의도로 사용되었는지 엄밀히 표현하지 못한다. 또한 잘못된 캐스팅에 대해서도 컴파일러가 경고를 못하는 경우가 발생한다.
C++에서는 위의 문제를 해결하기 위해 4가지 종류의 캐스팅 연산자를 제공한다 각각의 연산자가 어떤 의도로 사용하는지 분명하게 표현할 수 있도록 했으며, 안전성을 높이기 위해 각각의 캐스팅 연산자마다 제약을 두었다. 이제 이를 하나씩 알아보자.
1. static_cast
타입 원칙에 입각해, 상식적인 캐스팅만 허용
예를 들어 primitive type 간 변환이 여기에 속한다. int <-> float 타입 간 변환은 의미를 유지할 수 있기 때문에 '상식적'이라 얘기할 수 있을 것이다.
- 예를 들어 3이란 정수를 int 타입 변수에 저장했는데, 이를 float 타입 변수로 변환해도 3.0이란 형태로 의미가 유지된다.
int main()
{
int hp = 100;
int maxHp = 200;
float ratio = hp / static_cast<float>(maxHp);
return 0;
}정수 간 나눗셈은 결과 또한 정수가 되기 때문에 두 수 중 하나는 float 타입으로 변환해줘야 한다. 이때 (float) maxHp와 같이 사용했었는데, 대신 위 코드와 같이 static_cast를 사용할 수 있다.
또는 상속 관계에 있는 클래스 간에, 부모 클래스에서 자식 클래스로 변환하는 다운 캐스팅도 이 연산자를 이용해 실현할 수 있다.
class Player
{
};
class Knight : public Player
{
};
int main()
{
Player* player = new Knight();
Knight* knight = static_cast<Knight*>(player);
return 0;
}위 코드를 보면 실제 데이터는 Knight이지만 편하게 관리하도록 부모 클래스 타입 변수에 할당하고 있다. 하지만 코드 상으로는 부모 클래스 인스턴스를 자식 클래스 타입 변수에 대입하는 불안전 변환이므로, 반드시 명시적으로 캐스팅을 해줘야 한다.
이러한 부모 <-> 자식 간 변환이 빈번하게 발생해 캐스팅도 빈번하게 사용되는데, 이런 경우에도 C-Style 캐스팅 연산자로 강제로 변환하는 대신 static_cast를 이용할 수 있다. "일부 Player는 Knight가 될 수 있다"라는 말이 되는 상황이므로, 타입 변환 원칙에 입각한 캐스팅을 수행하는 static_cast를 사용하는 것이 적절하다.
주의해야 할 건, static_cast는 안전성을 보장하지 않는다.
class Archer : public Player
{
};
int main()
{
Player* player = new Archer();
Knight* knight = static_cast<Knight*>(player);
return 0;
}위 코드처럼 Player를 상속받은 또 다른 클래스 Archer가 있을 때, Player 타입 변수에 Archer의 인스턴스가 할당됐다고 하자. 문법적으로는 "일부 Player는 Knight가 될 수 있다"라는 전제가 틀리지 않기 때문에 여전히 에러가 발생하지 않는다. 만약 Archer와 Knight가 전혀 다른 메모리 구조를 갖게 된다면 유효하지 않은 메모리 영역을 침범할 수 있으므로 주의해야 한다.
즉 static_cast는 실제로 들어있는 데이터의 타입을 명확히 인지한 상황에서 사용해야 한다. 위에서 활용한 방식은 type 변수를 두고, 변수에 들어있는 값에 따라 자식 클래스를 결정하는 식으로 안전장치를 두었었다. 아니면 후술 할 dynamic_cast를 이용하는 방법도 있다.
가장 자주 사용하는 캐스팅 연산자이며, 기존에 사용하던 C-Style 캐스팅의 대부분 상황을 static_cast가 대체하게 된다.
2. dynamic_cast
상속 관계에서 안전한 형변환을 지원
안전한 형변환을 지원하기 위해 RTTI(RunTime Type Information)라는 개념이 적용된다. 이는 런타임에 타입 정보를 확인할 수 있다는 의미로, '다형성'을 활용하는 성질이다.
C++에서 다형성을 지원하기 위해 메서드나 소멸자에 virtual 키워드를 추가해 동적 바인딩이 동작하도록 코드를 작성하는데, virtual 키워드를 추가하면 가상 함수 테이블이 클래스 내부에 자동으로 생성된다. 이때 생성되는 가상 함수 테이블을 이용하는 방식이다. 위 코드에서 static_cast 부분을 dynamic_cast로 바꿔보자.
int main()
{
Player* player = new Archer();
Knight* knight = dynamic_cast<Knight*>(player);
return 0;
}
'표현식 타입이 다형성이 아닙니다'라는 에러 메시지를 띄워준다. 현재 Player 클래스에 virtual 함수가 하나도 없어서 RTTI가 동작하기 않기 때문이다. 한 번 virtual 키워드를 추가해 보자.
class Player
{
public:
Player() {}
virtual ~Player() {}
};
virtual 함수가 추가됨에 따라 가상 함수 테이블이 추가되어, dynamic_cast가 실제 데이터 타입을 추적할 수 있게 되었다.
또한 dynamic_cast의 중요한 특징 중 하나는, 캐스팅 실패 시 nullptr을 반환한다는 점이다. 아래 코드를 통해 확인해 보자.
int main()
{
Player* player = new Archer();
Knight* k1 = static_cast<Knight*>(player);
Knight* k2 = dynamic_cast<Knight*>(player);
return 0;
}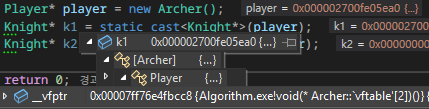

static_cast를 사용해 Knight로 변환한 k1은, 실제 데이터가 Archer이므로 Archer의 가상 함수 테이블을 가리키고 있다. 즉 잘못된 캐스팅이 발생한 것이다.
반면 dynamic_cast를 사용해 Knight로 변환한 k2는, 아예 nullptr가 반환되었다. 이 덕에 안전한 다운 캐스팅이 가능해진다.
다만 RTTI를 활용하는 방식 특성상, 캐스팅에 오버헤드가 존재해 static_cast보다 느리다는 단점이 있다. 그래서 실제 개발에는 dynamic_cast를 사용하는 경우도 있고, type 정보를 클래스에 들고 있도록 해서 이를 활용하는 방식을 사용하기도 한다.
3. const_cast
상수성을 추가하거나 제거하거나.
예를 들어 아래와 같은 외부 함수를 사용해야 한다고 가정하자. 외부 함수이기 때문에 우리는 시그니처를 수정할 수 없다.
void Print(char* str)
{
cout << str << "\n";
}우리가 아래와 같이 함수를 사용하려고 하면 컴파일 에러가 발생한다. 아래와 같이 문자열을 만들면 const char* 타입이 되기 때문이다.
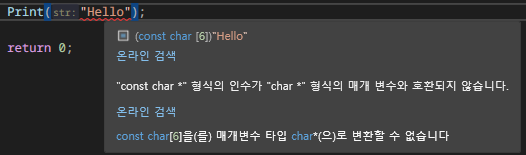
이 코드를 통과시키려면 const를 제거해줘야 한다. 이때 const_cast를 사용한다. 일반적인 C-Style 캐스팅과 달리 명확하게 "const를 제거한다"라는 의도가 명확하게 표현된다.
int main()
{
Print(const_cast<char*>("Hello"));
return 0;
}4. reinterpret_cast
강력한, 그만큼 위험한 캐스팅
이름 그대로 "재해석"하는 캐스팅 연산자이다. 보통 어떤 포인터를 전혀 관계없는 다른 타입으로 변환시킬 때 사용한다. 저장된 데이터의 비트열을 전혀 다른 방식으로 간주하겠다는 의미인데, 아래 코드로 확인해 보자.
int main()
{
Player* p = new Knight();
Knight* k = dynamic_cast<Knight*>(p);
long long address = k;
return 0;
}
현재 Knight의 인스턴스 k의 주소값을 long long 타입의 변수 address에 할당하고자 한다. 하지만 k는 포인터 변수이고 address는 정수이다 보니 암묵적 변환은 허용하지 않는다.
이전까지는 C-Style 캐스팅을 이용해 변환해 줬는데, 이런 경우에는 비트열을 완전히 변경하겠다는 의미의 reinterpret_cast를 사용하는 것이 적절하다.
int main()
{
Player* p = new Knight();
Knight* k = dynamic_cast<Knight*>(p);
long long address = reinterpret_cast<long long>(k);
return 0;
}아니면 상속 관계가 아닌, 전혀 연관 없는 클래스 간 캐스팅에도 사용할 수 있다.
- static_cast는 타입 변환 원칙에 입각한 상식적인 캐스팅에 동작하는데, 두 클래스 간에는 전혀 연관이 없기 때문에 논리적으로 말이 되지 않는다. 따라서 캐스팅이 되지 않는다.
class Dog
{
};
int main()
{
Player* p = new Knight();
Knight* k = dynamic_cast<Knight*>(p);
Dog* d = reinterpret_cast<Dog*>(k);
return 0;
}대표적으로 사용되는 경우는 C언어의 malloc 함수를 사용할 때이다. malloc 함수는 일정 크기의 메모리 공간을 할당하고 이에 대한 주소를 void* 타입으로 반환한다. 이를 Dog나 Knight와 같이 전혀 연관 없는 타입으로 사용하기 위해 C-Style 캐스팅 연산자를 사용해 왔지만, 비트열을 재해석해야 하는 상황이므로 reinterpret_cast를 사용하는 것이 적절하다.
'Computer Science > Programming Language' 카테고리의 다른 글
| [C++/Unreal] RTTI와 Reflection (0) | 2025.11.07 |
|---|---|
| [C++] 메모리 관리 2: 메모리 할당(Allocator) (6) | 2025.08.13 |
| [C++] 메모리 관리 1: 스마트 포인터 (6) | 2025.08.05 |
| [C++] 다형성(Polymorphism)과 가상 함수(Virtual Function) (2) | 2025.05.19 |