
0. 들어가기에 앞서

해당 포스팅은 널널한 개발자님이 업로드하신 위 영상을 글로 옮겨본 것이다.
예전에 모 회사 기술 면접에서 비슷한 질문이 나왔었는데, 당시에 제대로 대답하지 못했던 기억이 있다. 스택 메모리와 힙 메모리의 차이 정도는 알았지만, 그 '아는 정도'에서 나아가지 못하고 엉뚱한 소리를 해댔으니... 지금 돌이켜보면 참 부끄럽다. 다시는 그런 불상사가 일어나지 않도록, 관련 지식을 보충하고자 이번 글을 적게 되었다.
1. 질문의 핵심
하드웨어가 고도화되어 Stack 메모리의 크기가 매우 커질 수 있다면, 과연 Heap 메모리가 필요할까?
이 질문에 대한 핵심은 아래와 같이 정리할 수 있겠다.
- 컴퓨터 과학(CS) 이론에 대한 이해의 깊이를 알기 위한 질문이다.
- 큰 틀에서 보면 가상 메모리 시스템에 관한 질문이다.
- Stack 메모리와 Heap 메모리의 존재 이유에 관한 질문이다.
- 어느 정도의 정답이 있지만, 답변자의 수준에 따라 충분한 기술적 논의를 해볼 수 있는 질문이다.
이 질문은 CS 중 컴퓨터 구조론과 운영체제론, 그중에서 특히 가상 메모리와 관련된 내용이다. 사실 전공 서적을 확인해 보면 이 질문에 대한 해답이 이미 나와있다. 즉 관련 전공 내용을 제대로 숙지하고 있는가에 관해 묻는 질문이다.
1. Stack 메모리 관련 필수 답변
Stack 메모리와 Heap 메모리는 존재 목적 자체가 다르다.
현재로서는, 많은 언어들의 설계 구조 상 스택 메모리와 힙 메모리는 존재 목적이 다르기 때문에 이 둘은 같이 존재할 수밖에 없다. 왜 그런지 스택 메모리 특징을 알아보며 이해해 보자.
스택 메모리는 보통 함수의 지역변수, 매개변수, 반환주소 등에 사용되는 선형 메모리 공간이다. 이러한 함수 호출 관련 정보를 스택 프레임(stack frame)이라고 부른다. 그래서 스택 메모리는 함수 호출과 함께 할당되며, 함수 호출이 완료되면 소멸한다. 이 덕에 함수 호출이 모두 끝난 뒤에, 해당 함수가 호출되기 이전 상태로 되돌아갈 수 있다. 아래 예시 코드를 확인해 보자.
void func2()
{
}
void func1()
{
func2(); // func2 호출
}
int main()
{
func1(); // func1 호출
return 0;
}이 코드는 아래와 같이 동작한다.
- 프로그램이 실행되면 main() 함수가 호출되어 main() 함수의 스택 프레임이 스택에 저장된다.
- func1() 함수를 호출하면 해당 함수의 매개변수, 반환 주소값, 지역 변수 등의 스택 프레임이 스택에 저장된다.
- func2() 함수를 호출하면 해당 함수의 스택 프레임이 스택에 저장된다.
- func2() 함수의 모든 작업이 종료되면 func2() 함수의 스택 프레임이 스택에서 제거된다.
- func1() 함수의 호출이 종료되면 func1() 함수의 스택 프레임이 스택에서 제거된다.
- main() 함수의 모든 작업이 완료되면 main() 함수의 스택 프레임이 제거되면서 프로그램이 종료된다.

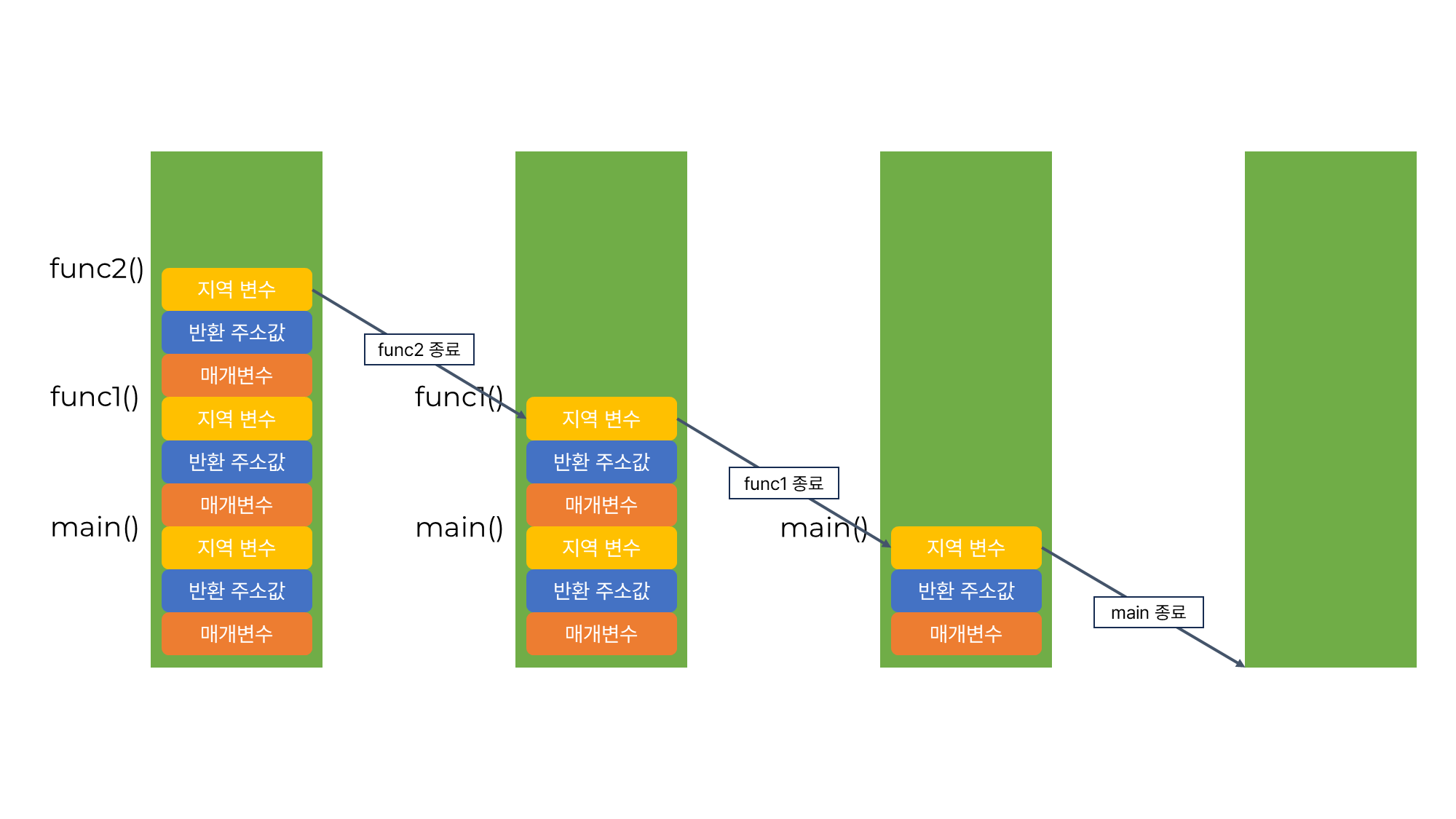
즉 스택은 가장 나중에 저장된 데이터가 가장 먼저 인출되는 후입선출(LIFO, Last-In First-Out) 방식으로 동작한다.
스택 프레임은 함수 호출 규약(Calling Convetion)에 따라 Caller가 제거할 수도 있고 Callee가 제거할 수도 있다. 함수 호출 규약은 1. 파라미터 전달 방법 2. 파라미터 전달 순서 3. 함수 리턴 값 전달 방법 4. 함수 호출 간 사용했던 스택 프레임을 정리하는 방법에 따라 종류가 나뉘는데, 여기서는 2가지 방식만 확인해 보겠다.
- __cdecl(C언어 표준): Caller가 정리한다. 이는 C언어의 printf()와 같은 가변 인자 함수 때문에 그렇다. 파라미터 값이 가변적이기 때문에, Callee에서 스택 프레임 정리를 일관되게 처리할 수 있는 루틴을 만들기 어렵다.
- __stdcall(Windows API): Callee가 정리한다. 윈도우 표준 함수의 경우에는 가변 인자 함수가 없고, 모든 함수의 파라미터가 고정되어 있다. Callee가 자기 자신의 스택 프레임을 정리하는 것이 더 효율적이기 때문에, Callee가 스택 프레임을 정리한다.
스택 메모리는 컴파일 타임에 필요한 메모리 공간의 크기를 확인할 수 있다는 특징이 있다. 다시 말해 기계어(혹은 바이트 코드)로 변환되기 전에, 컴파일 과정에서 소모되어야 할 스택 메모리의 크기를 알 수 있다는 뜻이다. 이는 곧 지역 변수의 수명을 추적할 수 있음을 의미한다.

위 이미지를 보면 func1 함수에서 int 타입 변수 a가 선언되었다. 선언된 시점부터 이름이 a인 메모리 공간이 필요해진 것이고, 함수 호출이 종료될 때 이 변수의 메모리 공간이 필요가 없어진다. 즉 함수 scope만큼 변수의 수명이 유지된다. 이는 함수의 지역변수이기 때문에 스택 프레임에 정보가 저장되고, 함수 호출-종료에 맞게 스택 프레임이 Push/Pop 되기 때문에 변수의 수명을 추적할 수 있는 것이다.
- 다만 VLA(Variable Length Array; 가변 길이 배열)와 같은 가변 스택 할당의 경우 해당 프레임의 크기는 런타임에 결정된다.
- 즉 애플리케이션이 실행되는 시점에 늘어나야 하는 스택을 정하는 코드를 작성할 수도 있는데, 이러한 경우 힙의 역할을 일부 대체할 수도 있다.
위에서 스택 프레임 그림을 보면 느낄 수도 있었을 텐데, 함수 호출 스택이 늘어날수록 논리적으로 비효율적인 코드일 가능성이 높다.
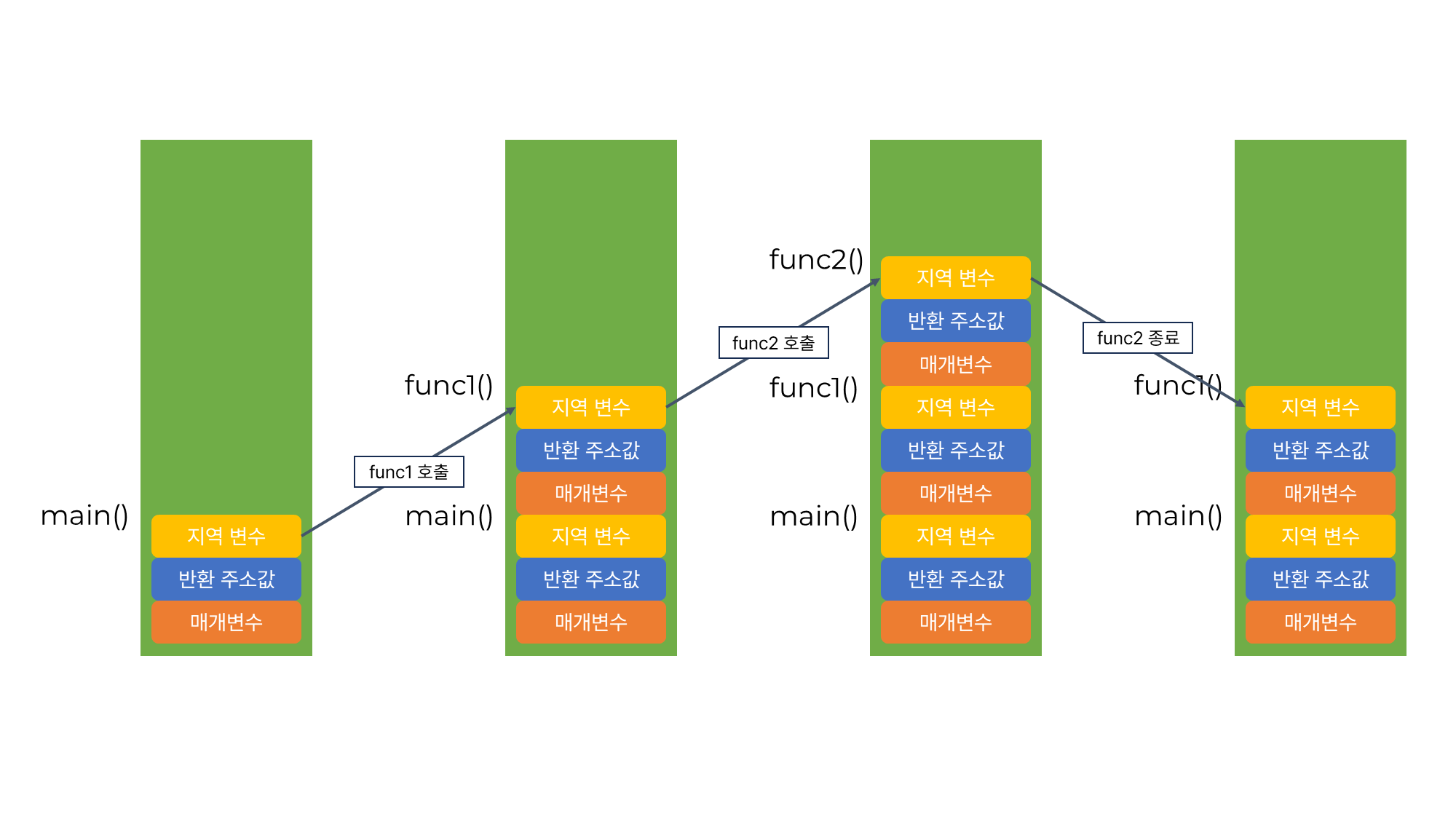
함수 호출 - 종료에 따라 스택 프레임이 위 그림과 같이 메모리에 Push / Pop 된다. 그런데 이렇게 함수 호출 Depth가 깊어질수록 코드 상에서 논리 흐름을 따라가기가 어려워진다. 함수의 추상화 수준이 높다면 문제가 덜 할 수도 있으나, 만약 func1 함수에서 에러가 발생한다면 func1 함수 만의 에러가 아니게 되기 때문에 디버깅도 어려워진다. func1을 기준으로 그 위에 쌓인 스택 프레임 모두를 추적해야 할 수도 있기 때문이다.
2. 스택과 멀티스레딩 이슈
스택의 구조 상 특정 함수 범위를 넘어서도 존재해야 하는 변수(혹은 인스턴스)를 관리하기 어렵다는 단점도 있다. 한 번 아래 그림을 확인해 보자.

func1() 함수에서 생성된 어떤 데이터가 여러 곳에서 참조해야 한다. 보통 이런 데이터는 동적 할당을 통해 힙 메모리에 올라가는 것이 일반적인데, 여기서는 스택 메모리만 존재한다고 가정해 보자. 그러면 해당 데이터 또한 스택 프레임에 기록되는데, 변수의 실제 생명 주기와 관계없이 func1() 함수의 스코프에 종속된다. 즉 func1() 함수 호출이 종료되면 해당 데이터 또한 메모리 상에서 제거된다. 이러면 해당 데이터를 참고하는 다른 곳에서는 해제된 메모리를 가리키게 되는 문제를 갖게 된다. 이는 다른 함수나 클래스뿐만 아니라, 멀티스레딩 환경에서 여러 스레드가 동시에 접근해야 할 필요성이 있는 경우에서도 똑같이 발생한다. 즉 구조적으로 데이터를 유지하는 것이 불가능하다.
2. 힙 메모리 파편화(Fragmentation)
int 변수 1개와 char 변수 1개는 각각 4Byte, 1Byte 크기를 갖는다. 이 두 타입의 변수를 갖는 구조체를 선언하면 실제 크기는 5Byte이지만, 운영체제가 할당해 주는 스택 메모리 크기는 8Byte이다.
int main()
{
struct A
{
int a;
char b;
};
A a;
cout << sizeof(a);
return 0;
}

그림처럼 1바이트 크기를 갖는 char 타입 변수 b에 3byte 크기의 padding을 붙여서 4byte로 취급한다. 그래서 구조체의 사이즈가 8byte로 출력되는 것이다. 여기서 만약 다른 변수를 선언하게 된다면 padding 자리를 차지하는 것이 아닌, 위에 쌓여서 메모리 공간을 차지하게 된다. 이렇게 4byte라는 폭이 유지되어 운영체제는 메모리 관리를 편리하게 할 수 있다. 이를 메모리 정렬(Memory Alignment)이라고 한다.
이러한 메모리 정렬은 하드웨어나 OS 수준에서도 이루어지는데, 보통 Page라는 이름의 단위로 관리한다. 윈도우에서는 GetSystemInfo() 함수를 통해 페이지 사이즈를 알 수 있다.
int main()
{
SYSTEM_INFO SystemInfo;
::GetSystemInfo(&SystemInfo);
cout << SystemInfo.dwPageSize;
return 0;
}
다만 위 그림에서 봤듯이, padding이라는 형식으로 부족한 공간을 의미가 없는 데이터로 채워버린다.

결국 OS에서 할당해 주는 메모리도 Page 단위이기 때문에, 인스턴스의 크기가 페이지 크기에 비례하지 않다면 낭비되는 공간이 생길 수밖에 없다. 이러한 현상을 내부 단편화라고 한다.
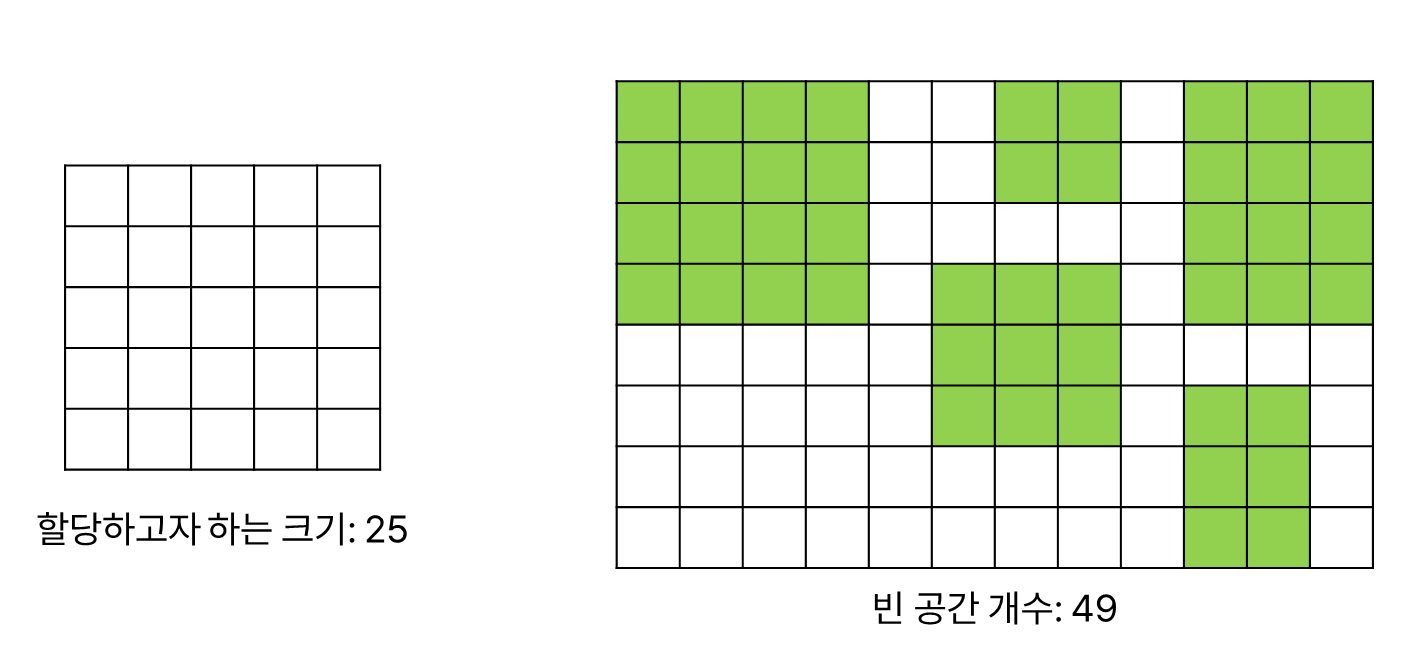
여기에 더해, 이전에 할당한 메모리 영역의 배치로 인해 빈 공간이 충분해도 요청한 크기를 할당해 줄 수 없는 문제가 생길 수도 있다. 이러한 현상을 외부 단편화라고 한다.
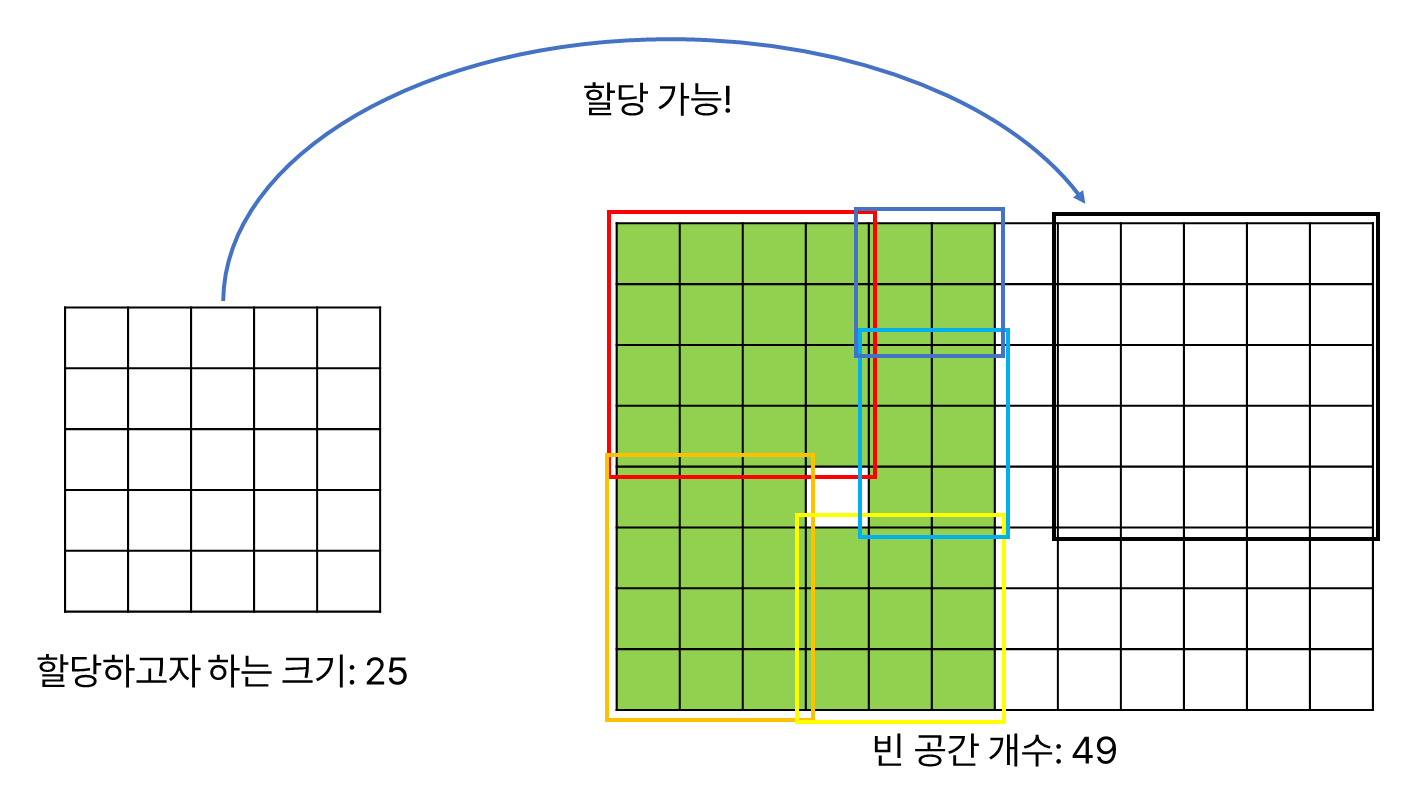
이러한 가변 분할 방식으로 메모리 공간을 할당했을 때 발생하는 외부 단편화는, 위 그림처럼 기존에 할당된 메모리 공간을 적절히 재배치하여 흩어진 빈 공간들을 하나의 큰 빈 공간으로 비우는 메모리 압축(compaction) 기법을 통해 해결할 수 있다. 이와 관련하여 더 자세한 내용은 다른 분이 작성하신 글을 참고해도 좋겠다.
메모리 풀
C언어에서 메모리를 동적으로 할당받고 해제하기 위해 API로 malloc(), free()를 사용한다. 그리고 C++의 new/delete 연산자 또한 내부적으로 malloc()/free()가 사용된다. 그런데 이 메모리 동적 할당 함수의 속도가 생각보다 느리다. 시스템 콜이기도 하고, 할당하기 적절한 공간을 찾는 과정도 있고, 할당받은 공간 해제 시 다른 공간과 병합하는 등 복잡한 작업이 내부적으로 이뤄지기 때문이다.
그래서 앞서 언급한 외부 단편화를 해결하면서, 성능을 개선하기 위해 게임 서버 같은 곳에서는 메모리 풀 기법을 적용하기도 한다. Pool은 마치 배열처럼 공간을 미리 할당해 두고 이를 재사용하는 방식을 의미한다.
보통 네트워크 패킷처럼 최대 크기가 이미 정해진 환경에서 매우 유리하다. 게임 서버의 경우, 접속하는 유저를 정의(id, 이름, 위치 등...)하는 클래스 내지 구조체가 있기 때문에 컴파일 타임에 크기가 고정된다. 따라서 이 단위로 할당할 메모리 크기를 설정해서 메모리 풀 기법을 적용할 수 있다.
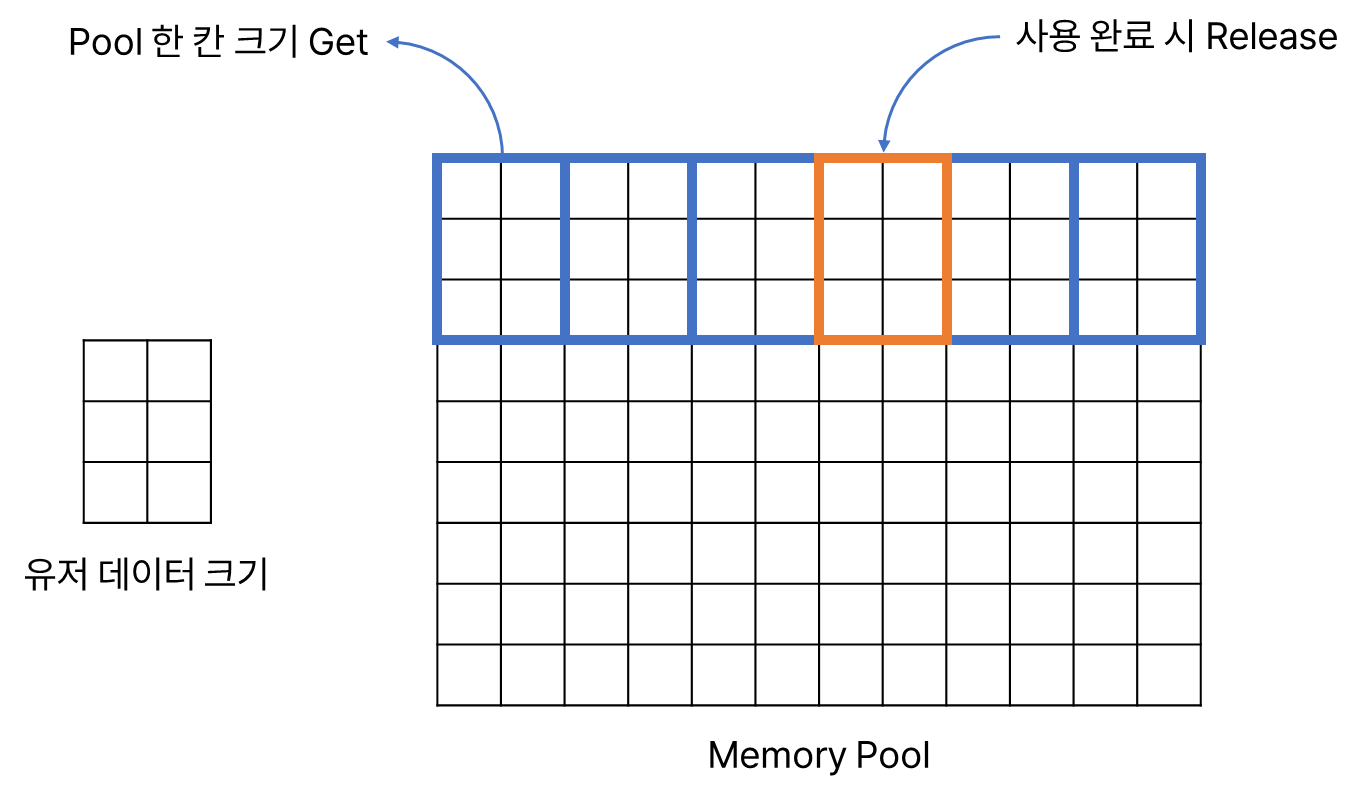
메모리 풀은 별도의 포스팅에서 직접 C++을 이용해 구현해보기로 하자.
3. 마무리
영상 속 내용을 옮겨보며, 베이스가 되는 지식을 점검하고 필요한 부분을 보충해 보았다. 영상에서는 다뤘지만 이번 포스팅에서 다루지 않은 내용(예: JVM의 Mark-Compact 알고리즘 등)도 있다. 이러한 부분들도 한 번씩 찾아보며 부족한 지식을 잘 채워보면 좋겠다.
'Computer Science > Operating System' 카테고리의 다른 글
| 가상 메모리 (0) | 2025.10.17 |
|---|---|
| 프로세스와 스레드 (3) | 2025.10.13 |
| 운영체제의 큰 그림 (0) | 2025.05.09 |